IOTA is structured around three core roles: the Orchestrator, Miners, and Validators. Rather than using a fully peer-to-peer topology, IOTA adopts a hub-and-spoke architecture centered around the Orchestrator. This design choice ensures global visibility and facilitates comprehensive monitoring of all participant interactions, which is essential for enforcing incentives, auditing behavior, and maintaining system integrity.
The Orchestrator’s primary responsibility is to monitor the training progress of each miner across all discrete layers and initiate weight-merging events accordingly. Given the heterogeneous nature of miner hardware and their unreliability, it is impractical to wait for all miners to complete an equal number of batches. Instead, a minimum batch threshold is defined for each miner, and once at least a specified fraction of miners complete the required number of batches, the Orchestrator prompts all qualifying miners to upload their weights. This mechanism is inspired by centralized training practices, where global batch sizes are used in typical large language model training. In the decentralized setting, it is coupled with DiLoCo, which allows miners to perform local optimization steps before synchronization. DiLoCo is especially suited for this paradigm because it:
- Embraces partial participation from miners
- Supports asynchronous and layer-wise updates
- Reduces communication overhead by focusing on the most informative coordinate updates locally
Miners can register for the subnetwork at any time. Upon registration, the Orchestrator assigns each miner a model layer to train. Miners will wait until the next full synchronization period to begin active participation. During full synchronization, miners update their weights and optimizer states to align with the rest of the network, allowing them to proceed with the forward and backward activations in the training stage.
Validators play a key role in determining whether the work completed by a miner is valid. Validators rely on computational reproducibility to validate the work. The validator tracks a specific miner and reruns a portion of the miner’s training to verify its accuracy. Forward and backward passes are compared to the miner’s submitted activations using cosine similarity. While there are challenges related to reliable validation, these are addressed in the system’s incentive structure and in later sections of the documentation, which explore anomaly detection and adversarial robustness using Shapley values.
The incentive structure is designed with the trade-offs between optimization and reproducibility in mind. Since validation depends on the validator’s ability to reproduce specific sections of the training process, miners are not granted the ability to innovate algorithmically. Validators monitor randomly assigned miners during full synchronization stages to ensure comprehensive oversight. The monitoring period is kept as short as possible to maximize the number of miners overseen by each validator. Importantly, miners are not aware of when they are being monitored, preventing them from selectively behaving correctly during observed intervals. After each validation stage, mining rewards are calculated based on the number of backward passes successfully processed by each miner.
The system incorporates a temporal decay mechanism governed by a hyperparameter, which determines how long a miner’s score is valid. After a fixed period, the score drops to zero. This ensures that miners are only rewarded for their active participation during validation periods, discouraging gaming strategies or manipulation of throughput during non-validation stages. The simple linear reward structure ensures that miners receive fixed compensation for each processed activation, and the recomputation requirement during validation stages provides additional security against exploitation.
IOTA Mining Setup
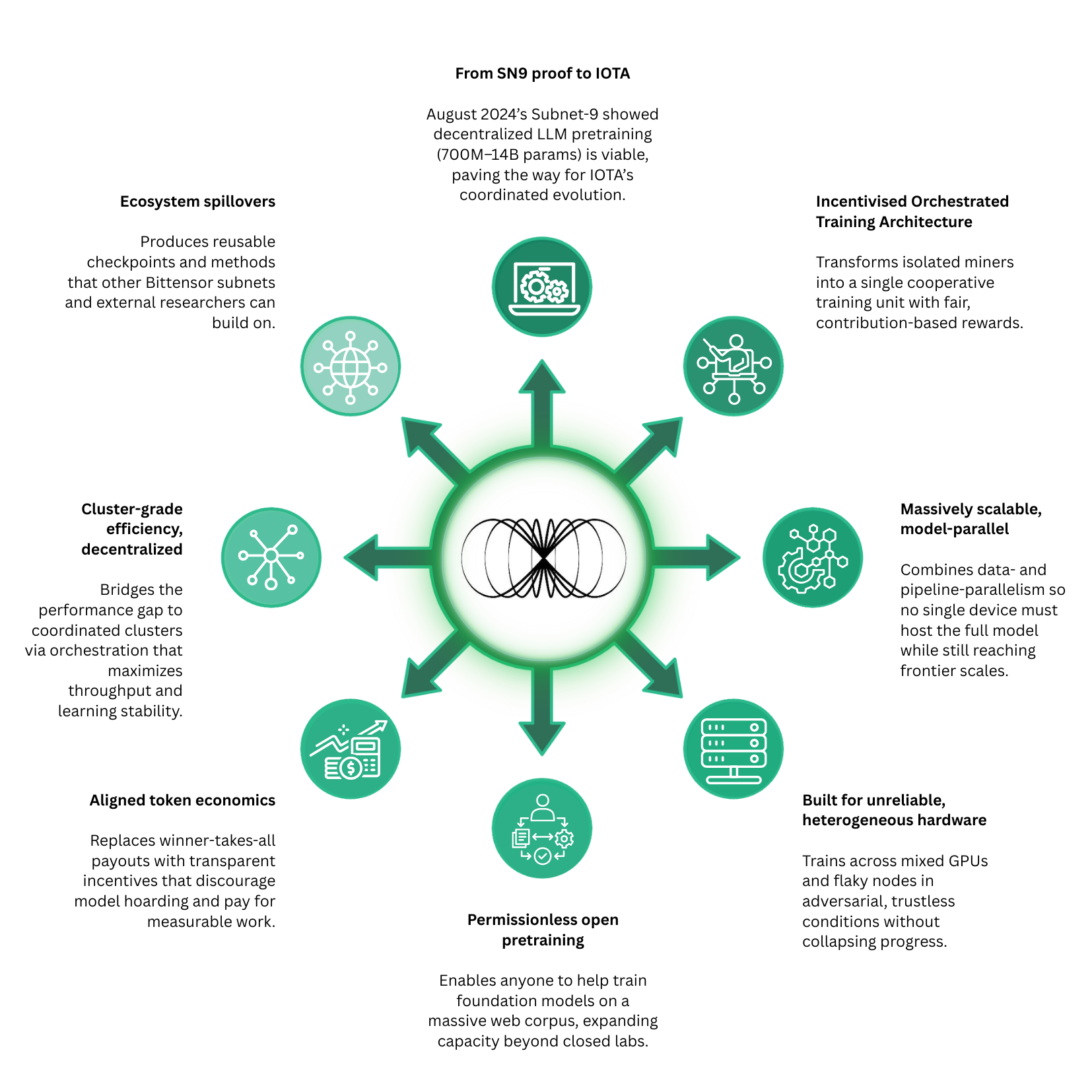
IOTA (Incentivized Orchestrated Training Architecture) is a data- and pipeline-parallel training algorithm designed to operate across a network of heterogeneous, unreliable devices in adversarial and trustless environments.
Miners’ Purpose in IOTA
In the decentralized LLM-training network, miners are responsible for providing GPU compute, memory, and bandwidth to collaboratively train models. IOTA employs data- and pipeline-parallelism, which means miners are responsible for training sections of the model instead of the entire model. This approach reduces hardware requirements for participation. Miners download their assigned section, process forward and backward passes of activations, and periodically synchronize their weights with peers via a merging process. Distributing workloads across many independent miners allows the network to achieve massive parallelism, fault tolerance, and censorship resistance while eliminating single-point infrastructure costs.
The IOTA incentive mechanism continuously scores miners based on throughput and the quality of their work throughout the training and merging processes. Miners are rewarded with subnet 9 alpha tokens according to the quality of their contributions.
Joining the Network
Miners can join the network and register with the orchestrator using their API client, which assigns them to a training layer. Up to 50 miners can operate per layer. Once registered, miners download the current global weights for their assigned layer and begin processing activations.
Activations
There are two types of activations: forward and backward.
- Forward activations propagate samples through the model to calculate losses.
- Backward activations propagate samples in the opposite direction to produce gradients for training the layer’s weights.
Backward activations are given precedence as they provide the learning signal. If a miner fails to process an activation assigned to it, a penalty is applied. This design operates like an assembly line, where workers pass between adjacent stages of the process. The flow of samples through the pipeline is randomized and stochastic.
Activation processing occurs across all layers simultaneously, but miners process samples asynchronously. Miners are incentivized to process as many activations as possible in each epoch, with their scores based on throughput.
Merging
Once enough samples have been processed in the network, the orchestrator signals the transition from training mode to merging mode. In this phase, miners engage in a multi-stage process based on a modified version of the Butterfly All-Reduce technique.
- Miners upload their local weights and optimizer states to the cloud storage.
- They are then assigned random weight partitions, with multiple miners assigned to the same partitions for redundancy and improved fault tolerance.
- Miners download their partitions, perform a local merge (currently using the element-wise geometric mean), and upload the merged partitions.
- Finally, miners download the complete set of merged weights and optimizer states.
This process is designed to tolerate miner failures, so merging can continue even if some miners fail during this stage. Merging is the slowest part of the process, so the training stage runs for longer to amortize this delay by effectively training on larger batch sizes. After merging is complete, the orchestrator returns the system to training mode, and the cycle continues between training and merging modes.
Prerequisites
To begin setting up the miner on IOTA, the following are required:
- Bittensor wallet – Setup instructions are available in the documentation.
- Training infrastructure – Miners must operate on GPUs with at least 80 GB of VRAM (A100-class or higher). Hardware with less memory will process updates more slowly and may earn significantly lower rewards.
- HuggingFace Access token – Basic access to pull the model from HuggingFace. There is no need to modify permissions.
Validating
Within the system, validators have a vital role in ensuring the integrity of the work completed by miners. They primarily rely on computational reproducibility to verify the miner’s work. To do so, the validator tracks a specific miner and reruns a portion of the miner’s training. This includes checking both forward and backward passes against the miner’s submitted activations using cosine similarity. However, reliable validation presents several challenges, which are further explored in the following sections.
Joining the Network
Validators join the network by registering with the orchestrator through their API client.
Shadowing Miners
Validators periodically reproduce an epoch’s worth of work from a randomly selected miner. This process can take up to an hour per miner in the current version, and efforts will be made to reduce this time post-launch. There is a tradeoff between the effective batch size and network stability—validators have more work to reproduce when scoring a miner during longer training stages. The system currently relies on basic and robust reproducibility checks, though a future integration of CLASP will enable an auditor-like mechanism to estimate miner contributions. Once a validator confirms that all activations were processed correctly by the miner, they perform a local all-reduce to compare their own local weights and optimizer state with those uploaded by the miner. If the miner passes the check, they earn a score based on the total number of activations processed during that period.
Setting Weights
Validators communicate through the orchestrator, submitting the scores they assign to miners after performing spot checks. These scores are pooled together to calculate a consensus score for each miner. Periodically, validators request miner scores from the orchestrator, normalize the data, and set weights. This process ensures agreement among validators and helps maintain a high level of trust within the validation system.