Starting the year incredibly grateful to our Open Source contributors.
Over the holidays, while working on a PR to migrate our Mechanism 0 DataLoader to R2, @jorritvangils spotted a critical bug in our miner code. He quickly merged a fix (PR #87: ) to

Fix dataloader and blocklist block mismatch by JorritvanGils · Pull Request #87 · dstrbtd/Distrib...
Currently, self.current_block is updated continuously, causing a mismatch between the value passed to DatasetLoader.next_pag...
github.com
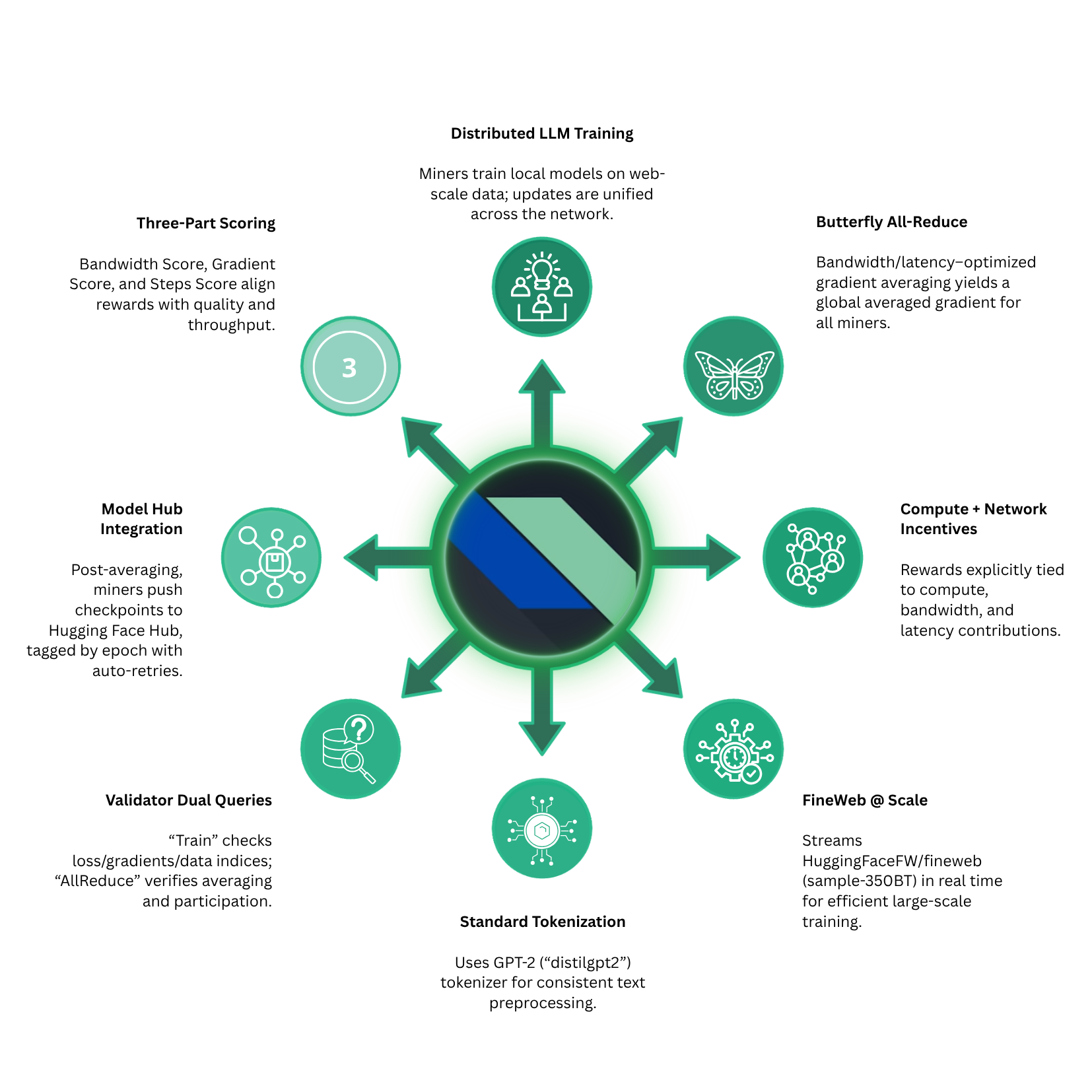
Last Friday, we launched Mechanism 1 on Subnet 38's main-net! 🚀
Mechanism 1 is a winner-takes-all mechanism that aims to incentivise miners to develop SOTA distributed training strategies (see the "Aggregation" row in the heat-map in the attached post).
These optimised

Decentralized pre-training has accelerated rapidly over the past year, with multiple teams running public experiments each taking a different approach to the same problem.
Here is a high-level comparison across sharding strategy, permissions, model scale, aggregation, and
Decentralized pre-training has accelerated rapidly over the past year, with multiple teams running public experiments each taking a different approach to the same problem.
Here is a high-level comparison across sharding strategy, permissions, model scale, aggregation, and
It's worth noting that there are also excellent teams like Nous Research, Grail and Gensyn working on decentralized post-training.
This thread focuses specifically on decentralized pre-training, where the size and type of information being shared are quite different. Both
If we’ve missed out any other public decentralized pre-training efforts, we’d love for people to share them with us.
Especially interested in protocols exploring novel aggregation techniques, compression algorithms or incentive mechanisms.
A question we often get from members of our community is: "in layman's terms what is DSTRBTD's long term vision?"
Put simply, its building community owned artificial intelligence.
Right now, the world’s most powerful AI is owned and controlled by a small number of large
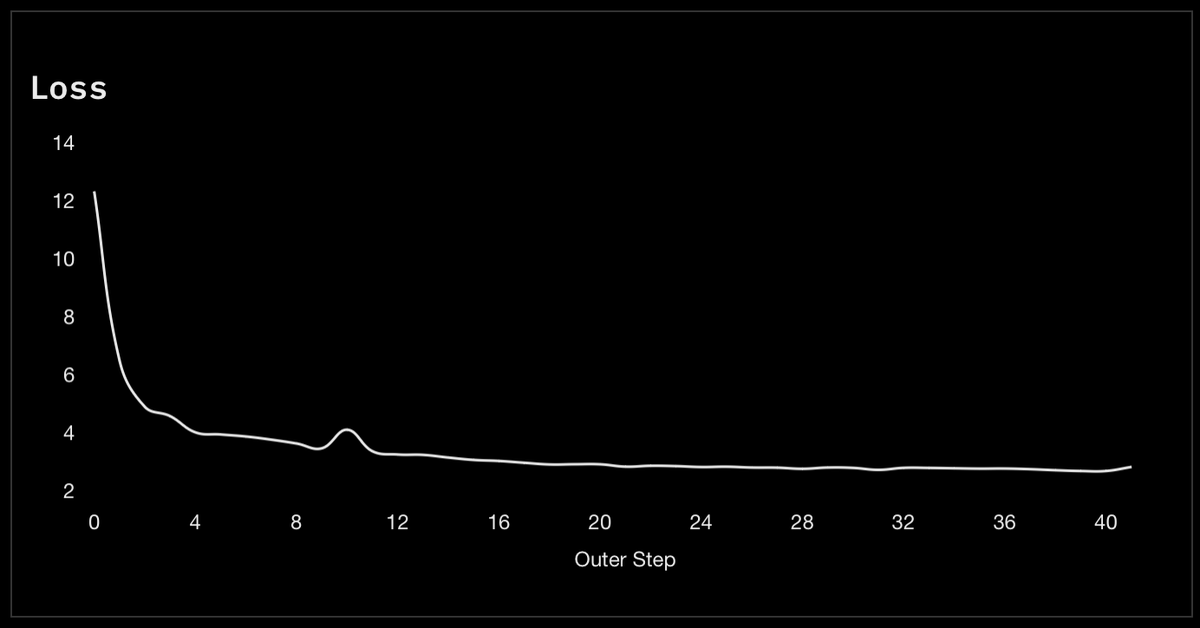
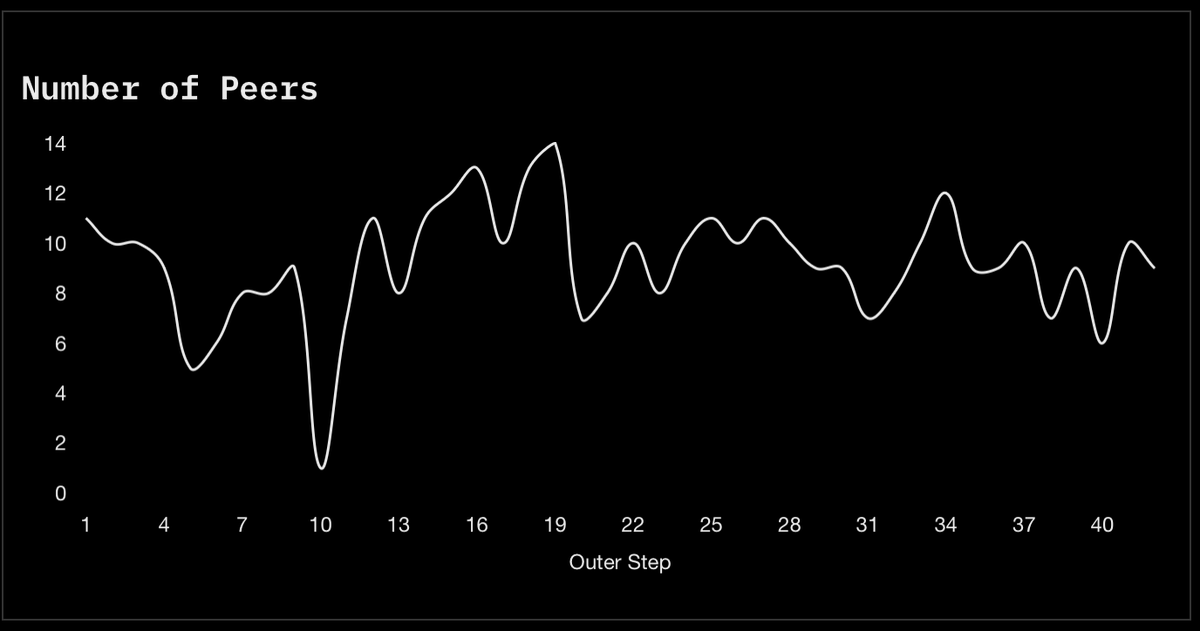
DSTRBTD’s Run 4 is our most stable attempt to date at training a 4B parameter model in a fully permission-less, trust-less and decentralised setting: https://dash.dstrbtd.ai/performance.
Over the past week, we’ve seen an average of 10 participants per AllReduce (the process of sharing
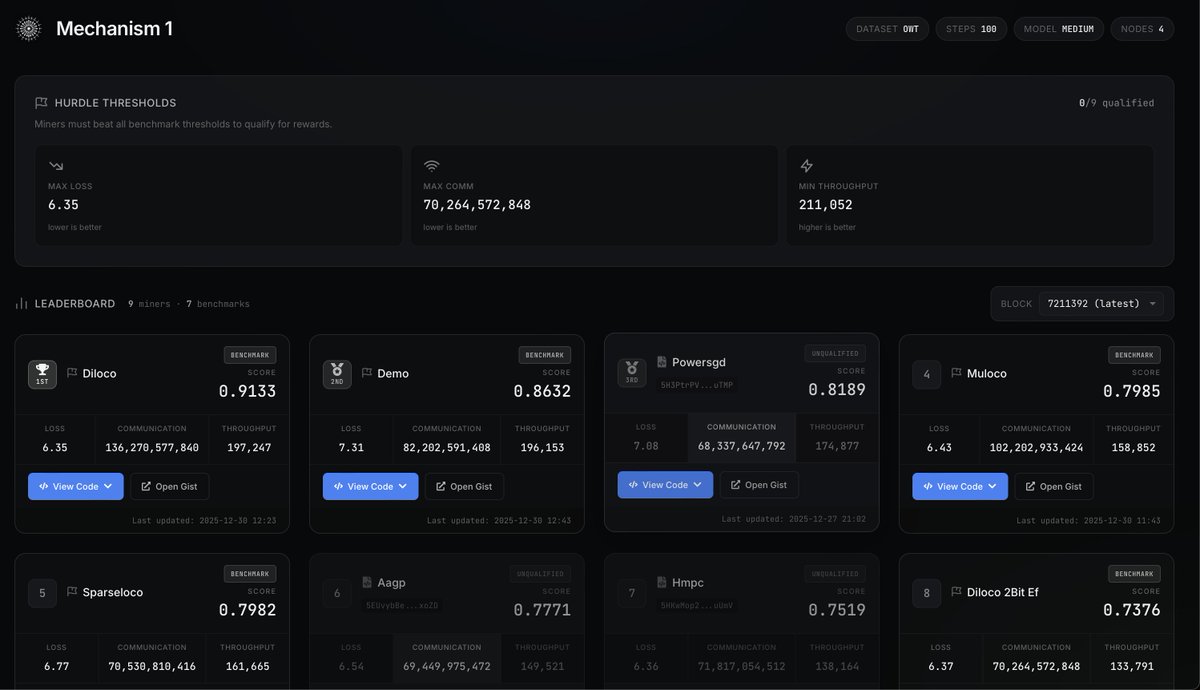
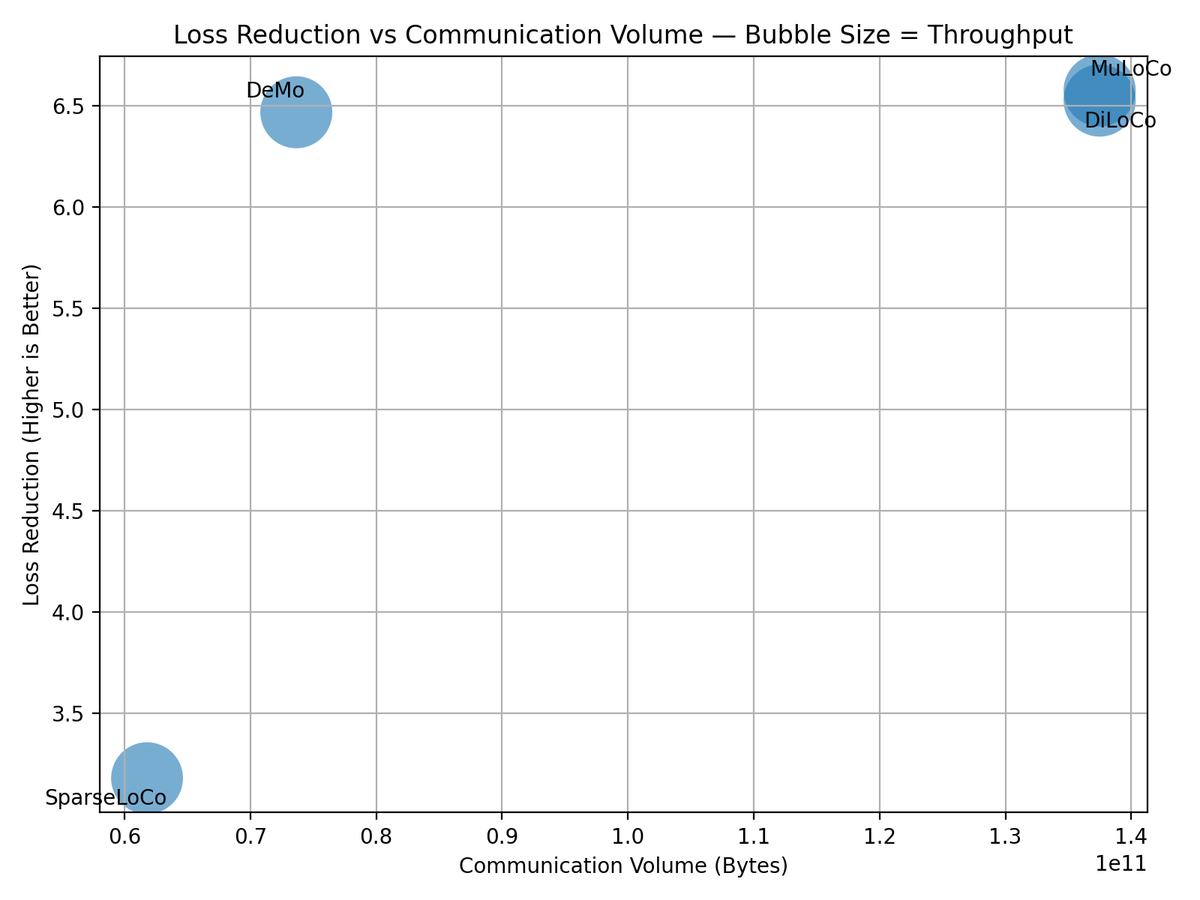
DSTRBTD's Mechanism 1 is now producing reproducible benchmarks for distributed training optimizers.
Each optimizer is evaluated in a sandbox environment that trains NanoGPT variants for 10k steps. We record:
• Final Loss
• Communication Volume
• Throughput
These metrics are